Machine Vision Goals – Part 1
Tags: control, innovate, and softwarePersonhours: 5
We’ve been using machine vision for a couple of years now and have a plan to use it in Relic Rescue for a number of things. I mostly haven’t gotten to it because college application deadlines have a higher priority for me this year. But since we already have experience with color blob tracking in OpenCV and Vuforia tracking, I hope this won’t be too difficult. We have 5 different things we want to try:
VuMark decode – this is obvious since it gives us a chance to regularly get the glyph crypto bonus. From looking at the code, it seems to be a single line different from the Vuforia tracking code we’ve already got. It’s probably a good idea to signal the completed decode by flashing our lights or something like that. That will make it more obvious to judges and competitors.
Jewel Identification – most teams seem to be using the REV color sensor on the arm their jewel displacement arm. We’ll probably start out doing that too, but I’d also like to use machine vision to identify the correct jewel. Just because we can. Just looking at the arrangement, we should be able to get both the jewels and the Vuforia target in the same frame at the beginning of autonomous.
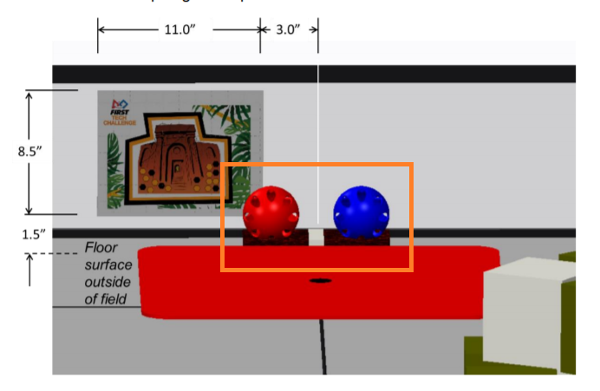
Alignment – it is not legal to extend a part of the robot outside of the 18” dimensions during match setup. So we can’t put the jewel arm out to make sure it is between the jewels. But there is nothing preventing us from using the camera to assist with alignment. We can even draw on the screen where the jewels should appear, like inside the orange box below. This will also help with Jewel ID – we won’t have to hunt for the relevant pixels – we can just compare the average hue of the two regions around the wiffle balls.
Autonomous Deposition – this is the most ambitious use for machine vision. The dividers on the crypto boxes should make pretty clear color blob regions. If we can find the center points between these regions, we should be able to code and automatically centering glyph depositing behavior.
Autonomous glyph collection – ok this is actually harder. Teams seem to spend most of their time retrieving glyphs. Most of that time seems to be spent getting the robot and the glyphs square with each other. Our drivers have a lot of trouble with this even though we have a very maneuverable mecanum drive. What if we could create a behavior that would automatically align the robot to a target glyph on approach? With our PID routines we should be able to do this pretty efficiently. The trouble is we need to figure out the glyph orientation by analyzing frames on approach. And it probably means shape analysis – something we’ve never done before. If we get to this, it won’t be until pretty late in the season. Maybe we’ll come up with a better mechanical approach to aligning glyphs with our bot and this won’t be needed.
Tools for Experimenting
Machine vision folks tend to think about image analysis as a pipeline that strings together different image processing algorithms in order to understand something about the source image or video feed. These algorithms are often things like convolution filters that isolate different parts of the image. You have to decide which stages to put into a pipeline depending on what that pipeline is meant to detect or decide. To make it easier to experiment, it’s good to use tools that let you create these pipelines and play around with them before you try to hard-code it into your robot.
I've been using a tool called ImagePlay. http://imageplay.io/ It's open source and based on OpenCV. I used it to create a pipeline that has some potential to help navigation in this year's challenge. Since ImagePlay is open source, once you have a pipeline, you can figure out the calls to it makes to opencv to construct the stages. It's based on the C++ implementation of OpenCV so we’ll have to translate that to java for Android. It has a very nice pipeline editor that supports branching. The downside is that this tool is buggy and doesn't have anywhere near the number of filters and algorithms that RoboRealm supports.
RoboRealm is what we wanted to use. We’ve been pretty closely connected with the Dallas Personal Robotics Group (DPRG) for years and Carl Ott is a member who has taught a couple of sessions on using RoboRealm to solve the club’s expert line following course. Based on his recommendation we contacted the RoboRealm folks and they gave use a 5 user commercial license. I think that’s valued at $2,500. They seemed happy to support FTC teams.
RoboRealm is much easier to experiment with and they have great documentation so now have an improved pipeline. It's going to take more work to figure out how to implement that pipeline in OpenCV because it’s not always clear what a particular stage in RoboRealm does at a low level. But this improved pipeline isn’t all that different from the ImagePlay version.
Candidate Pipeline
So here is a picture of a red cryptobox sitting against a wall with a bunch of junk in the background. This image ended up upside down, but that doesn’t matter for just experimenting. I wanted a challenging image, because I want to know early if we need to have a clean background for the cryptoboxes. If so, we might need to ask the FTA if we can put an opaque background behind the cryptoboxes:

Stage 1 – Color Filter – this selects only the reddest pixels

Stage 2 – GreyScale – Don’t need the color information anymore, this reduces the data size

Stage 3 – Flood Fill – This simplifies a region by flooding it with the average color of nearby pixels. This is the same thing when you use the posterize effect in photoshop. This also tends to remove some of the background noise.

Stage 4 – Auto Threshold – Turns the image into a B/W image with no grey values based on a thresholding algorithm that only the RoboRealm folks know.

Stage 5 – Blob Size – A blob is a set of connected pixels with a similar value. Here we are limiting the output to the 4 largest blobs, because normally there are 4 dividers visible. In this case there is an error. The small blob on the far right is classified as a divider even though it is just some other red thing in the background, because the leftmost column was mostly cut out of the frame and wasn’t lit very well. It ended up being erased by this pipeline.

Stages 6 & 7 – Moment Statistics – Moments are calculations that can help to classify parts of images. We’ve used Hu Moments since our first work with machine vision on our robot named Argos. They can calculate the center of a blob (center of gravity), its eccentricity, and its area. Here the center of gravity is the little red square at the center of each blob. Now we can calculate the midpoint between each blob to find the center of a column and use that as a navigation target if we can do all this in real-time. We may have to reduce image resolution to speed things up.
