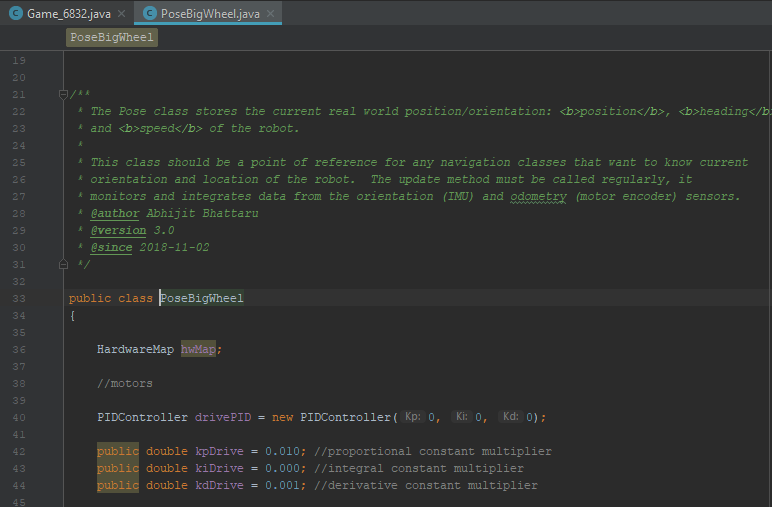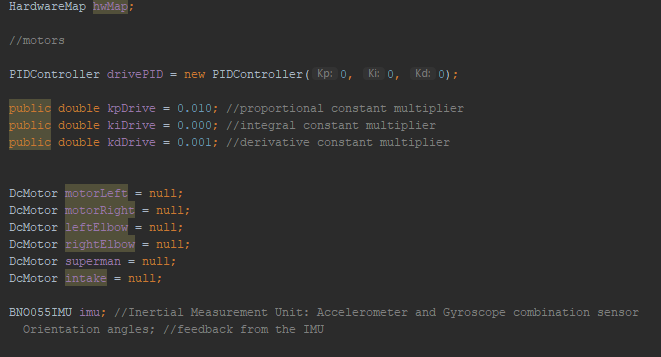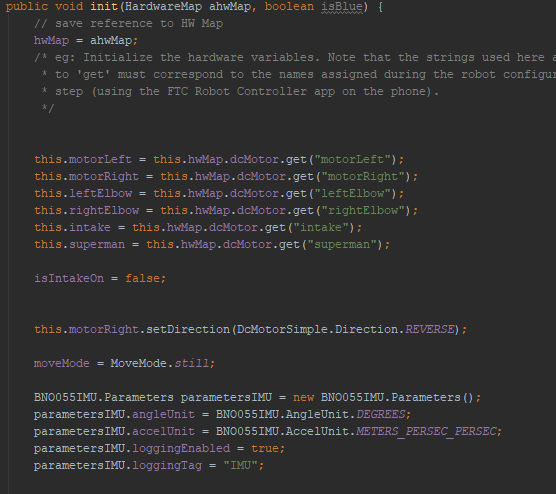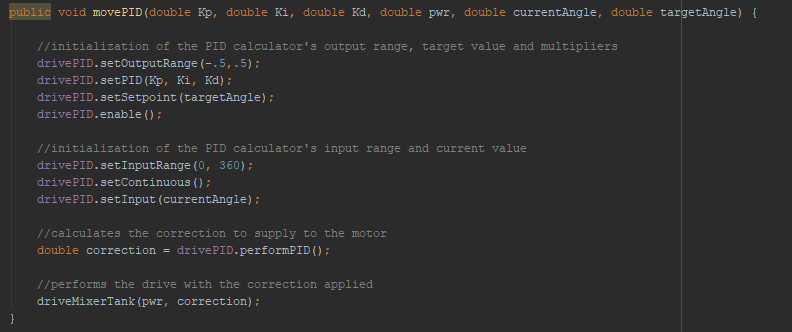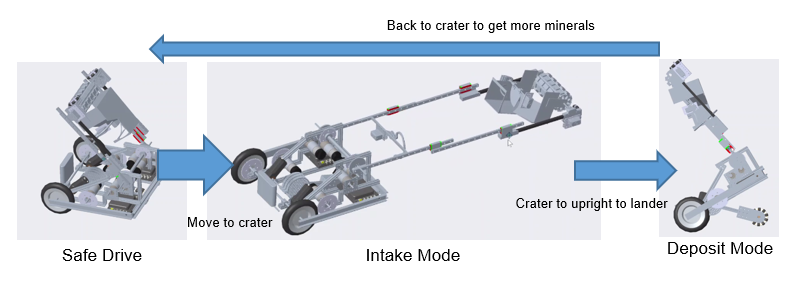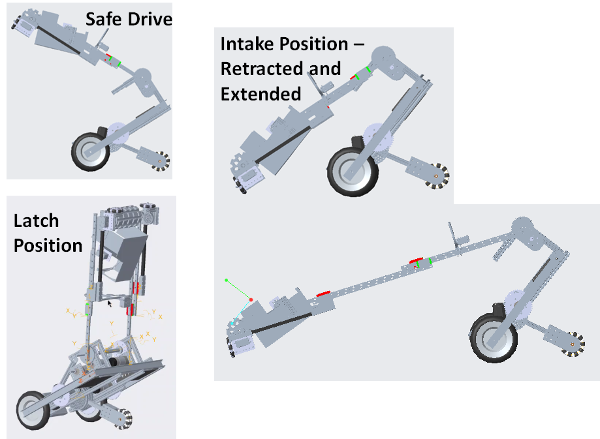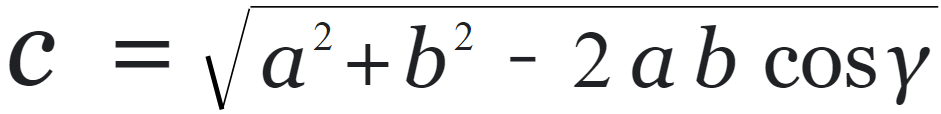
Position Tracking
Task: Design a way to track the robot's location

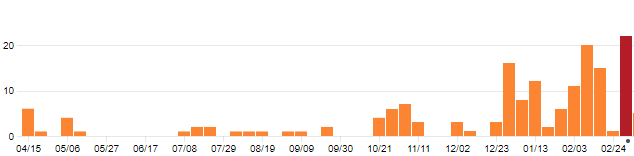
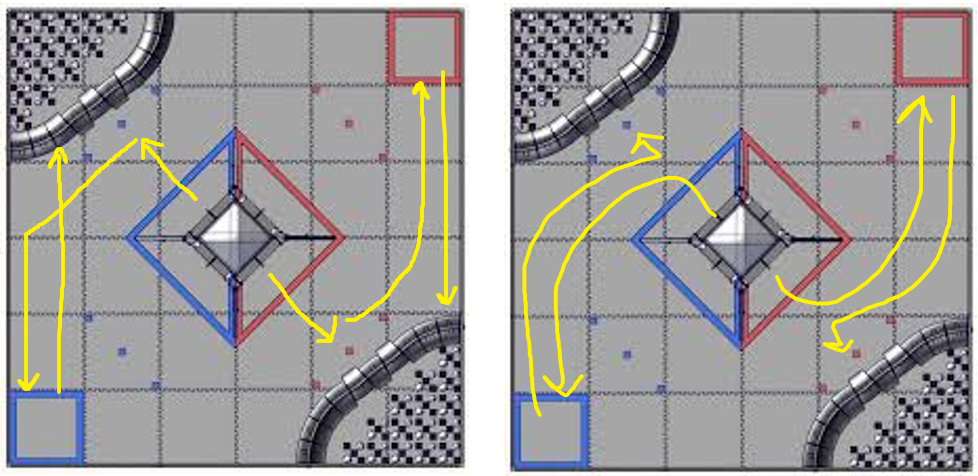
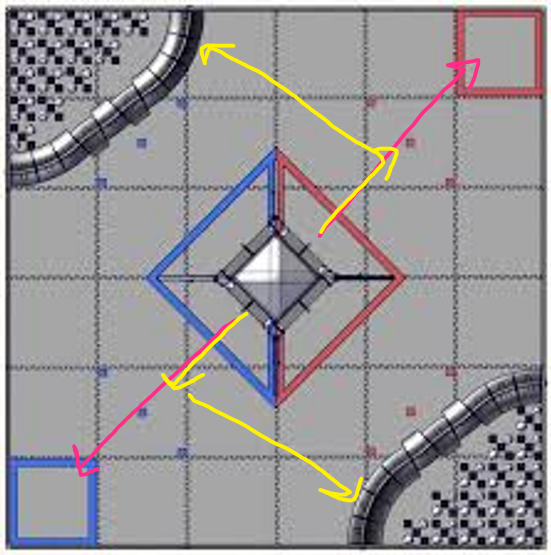
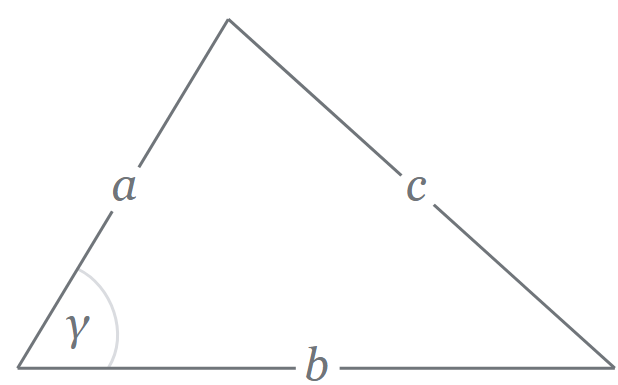
During Relic Recovery season, we had many problems with our autonomous due to slippage in the mecanum wheels and our need to align to the balancing stone, both of which created high error in our encoder feedback. To address this recurring issue, we searched for an alternative way to identify our position on the field. Upon researching online and discussing with other teams, we discovered an alternative tracker sensor with unpowered omni wheels. This tracker may be used during Rover Ruckus or beyond depending on what our chassis will be.
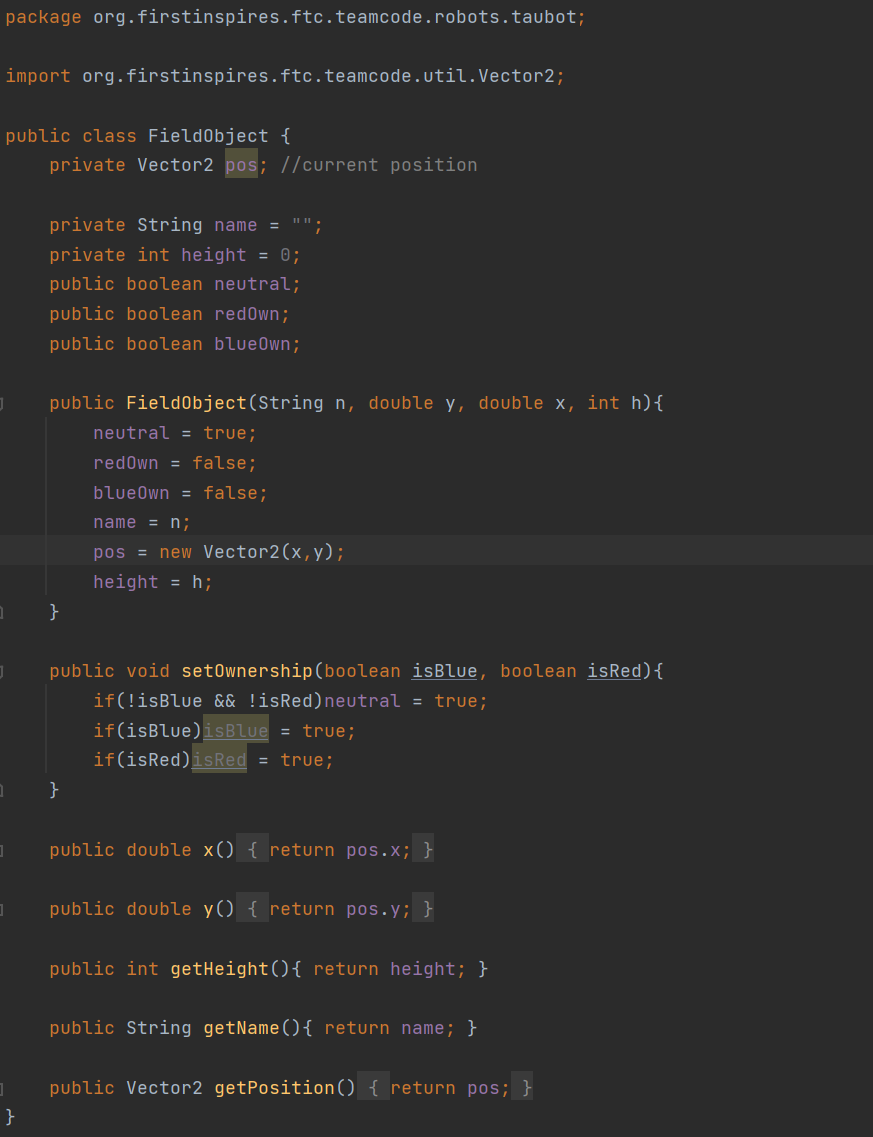
We designed the tracker by building a small right angular REV rail assembly. On this, we attached 2 omni wheels at 90 degrees to one another and added axle encoders. The omni wheels were not driven because we simply wanted them to glide along the floor and read the encoder values of the movements. This method of tracking is commonly referred to as "dead wheel tracking". Since the omnis will always be touching the ground, any movement will be sensed in them and prevents changes in readings due to defense or drive wheel slippage.
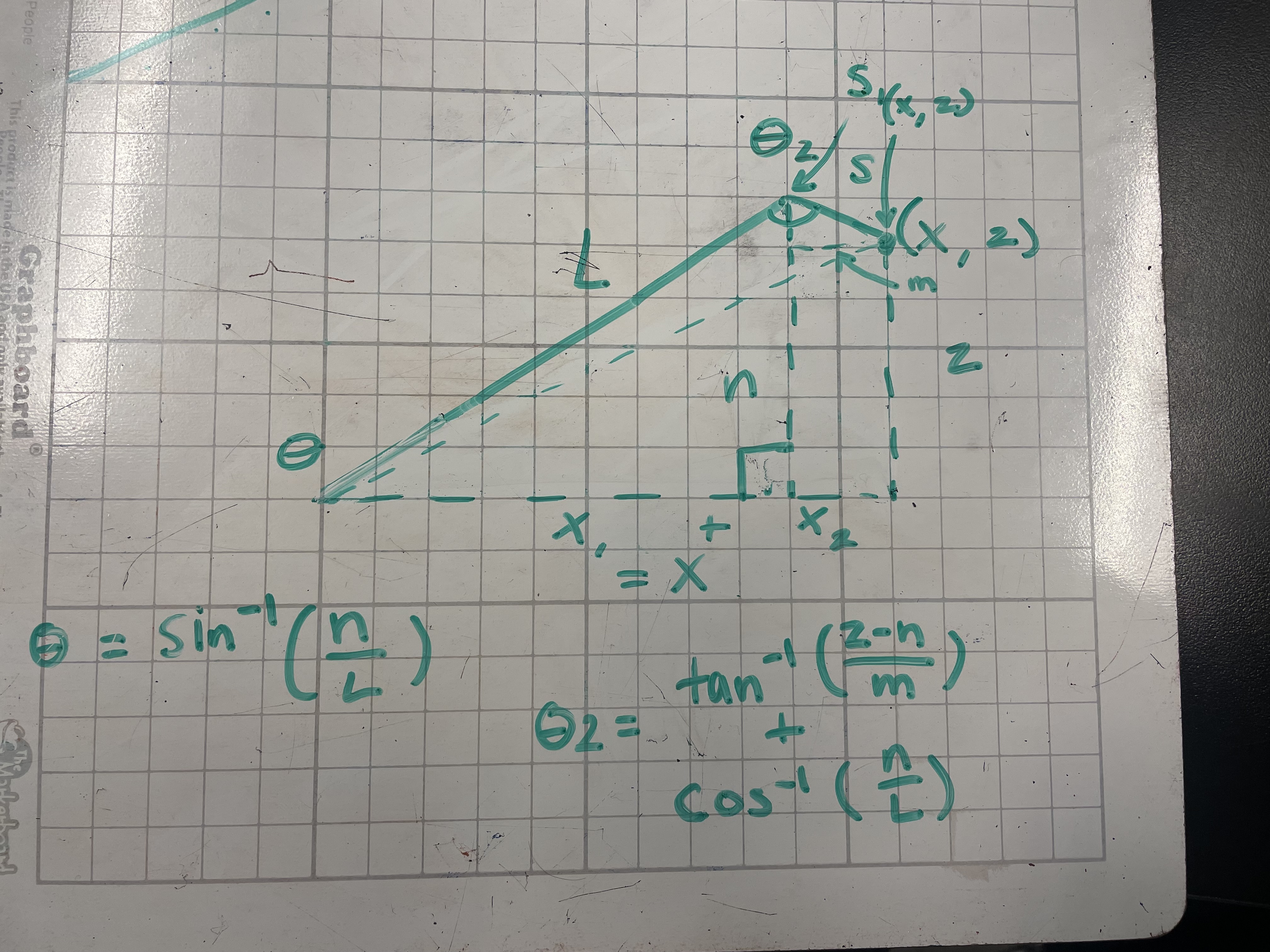
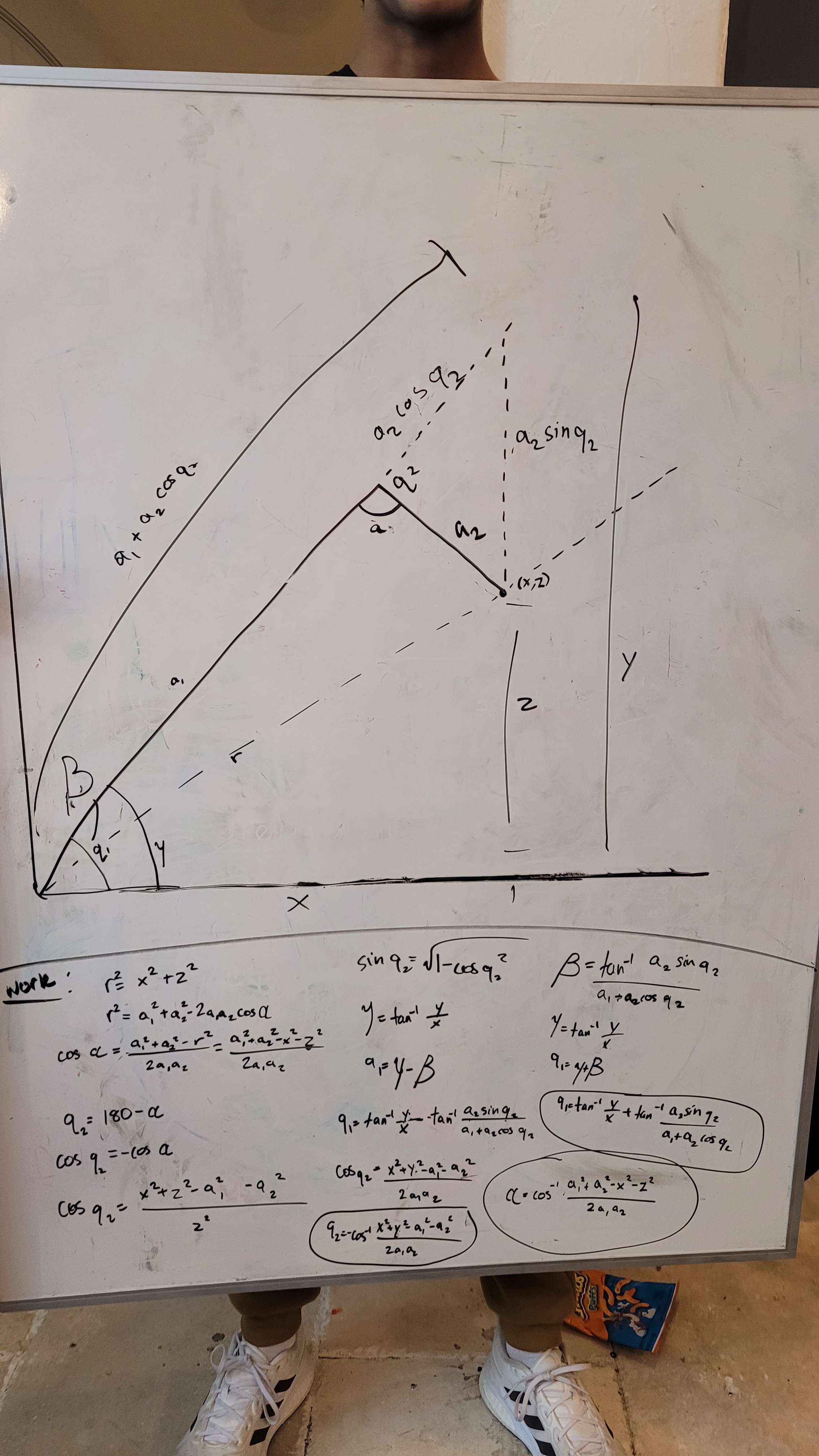
To test the concept, we attached the apparatus to ARGOS. With some upgrades to the ARGOS code by using the IMU and omni wheels, we added some basic trigonometry to the code to accurately track the position. The omni setup was relatively accurate and may be used for future projects and robots.
Next Steps
Now that we have a prototype to track position without using too many resources, we need to test it on an actual FTC chassis. Depending on whether or not there is terrain in Rover Ruckus, the use of this system will change. Until then, we can still experiment with this and develop a useful multipurpose sensor.